Разговор с Куок Ле: Эксперт по ИИ, стоящий за Google AutoML

Один из основателей Google Brain и разума, стоящего за AutoML, Куок Ле является естественным ИИ: он любит машинное обучение и любит автоматизировать вещи.
Ле использовал миллионы миниатюр YouTube для разработки неконтролируемой системы обучения, которая распознала кошек, когда он был доктором философии Стэнфордского университета в 2011 году. В 2014 году он продвинул производительность машинного перевода с помощью методов глубокого обучения и сквозной системы, которая автоматически преобразовывала слова и документы в векторные представления, заложив основу для последующих прорывов Google в области нейронного машинного перевода.

С 2014 года Ле нацелился на автоматизированное машинное обучение (AutoML). Процесс построения моделей машинного обучения по существу требует повторяющейся ручной настройки: исследователи пробуют различные архитектуры и гиперпараметры на исходной модели, оценивают производительность набора данных, возвращаются с изменениями, и процесс повторяется в направлении оптимизации.
Ле видит в этом простую пробную и ошибочную проблему, которую можно решить с помощью машинного обучения.
В 2016 году Ле объединился с резидентом Google и опубликовал фундаментальную статью "Нейроархитектурный поиск с дополнительным обучением". Основная идея была сродни строительным блокам: Машина забирает необходимые ей компоненты из заданного пространства для построения нейронной сети, а затем повышает ее точность, используя технику проб и ошибок, которая заключается в усиленном обучении. Результат был многообещающим, так как машины генерировали модели, которые соответствовали лучшим моделям производительности человека.
Исследования Ле внесли свой вклад в создание Google Cloud AutoML - набора инструментов, который позволяет разработчикам с ограниченным опытом машинного обучения обучать высококачественные модели. Неудивительно, что AutoML быстро стал популярной темой, поскольку как технические гиганты, так и стартапы следуют следам Google и делают ставки на новые технологии.
Synced недавно брал видеоинтервью с Ле. В широкомасштабном видео-интервью скромный 36-летний эксперт по искусственному искусству Вьетнама рассказал о своем вдохновении, технологиях и перспективах AutoML и его важной новой роли в области машинного обучения. Читайте дальше, чтобы понять человека, стоящего за столь многими преобразующими технологиями. Интервью было отредактировано для краткости и ясности.
На предстоящей 9 ноября конференции AI Frontiers в Сан-Хосе, штат Калифорния, Куок Ле выступит с докладом «Использование машинного обучения для автоматизации машинного обучения», уделив особое внимание поиску нейронной архитектуры и автоагрегату.
Вдохновение
Когда вы начали думать о разработке новой нейронной архитектуры поиска и что вас вдохновило?
Это происходит примерно в 2014 году и происходит постепенно с течением времени. Я инженер по машинному обучению. Когда вы постоянно работаете с нейронными сетями, вы понимаете, что многие из них требуют ручной настройки, то, что люди называют гиперпараметрами — количество слоев в нейронной сети, скорость обучения и какой тип слоев входит в эти сети. Исследователи ИИ, как правило, начинают с некоторых принципов, а затем со временем принципы как бы высвобождаются, и они пробуют разные вещи. Я следил за некоторыми разработками в конкурсах ImageNet и видел развитие сетей Inception в Google.
Я начал думать, но не был уверен, что хочу сделать. Мне нравятся сверточные сети, но мне не нравится тот факт, что веса в сверточной сети не разделяются друг с другом. Поэтому я подумал, что, возможно, мне следует разработать механизм, чтобы действительно научиться делиться весами в нейронной сети.
По мере того как я продвигался вперед, у меня появлялось все больше и больше интуиции на этот счет, и тогда я задумался, что же мне делать. Что делают исследователи, так это берут кучу существующих строительных блоков, а затем пробуют их. Они видят некоторое улучшение точности. А потом они говорят: "Хорошо, может быть, я просто предложил хорошую идею. Как насчет того, чтобы сохранить хорошие вещи, которые я только что представил, но заменить старые вещи чем-то новым?- Итак, они продолжают этот процесс — и специалист в этой области может попробовать сотни архитектур.
Примерно в 2016 году я начал думать, что если есть процесс, который требует так много проб и ошибок, мы должны автоматически использовать машинное обучение, потому что само машинное обучение также основано на пробах и ошибках. Если вы думаете об обучении подкреплению и о том, как машина научилась играть в игру Go, то это в основном метод проб и ошибок.
Я прикинул, сколько реальных вычислений мне понадобится для этого. Я думал, что человеку может потребоваться сотня сетей, потому что у людей уже есть много интуиции и много тренировок. Если вы используете алгоритм для этого, вы можете быть на один или два порядка медленнее. На самом деле я думал, что быть на один или два порядка медленнее было бы не так уж плохо, поскольку у нас уже было достаточно вычислительной мощности, чтобы сделать это. Поэтому я решил начать проект с резидента (Баррет ЗОФ, который теперь является исследователем Google Brain).
Я не ожидал, что это будет так удачно. Я думал, что самое лучшее, что мы можем сделать, - это, возможно, 80 процентов человеческой производительности, и это будет успех. Но резидент был настолько хорош, что действительно мог соответствовать человеческим характеристикам.
Многие люди говорили мне: "вы потратили так много ресурсов, чтобы просто соответствовать человеческому уровню?" Но то, что я увидел из этого эксперимента, было то, что автоматизированное машинное обучение теперь стало возможным. Это был просто вопрос масштаба. Поэтому, если вы масштабируете больше, вы получаете лучший результат. Мы продолжили работу над вторым проектом, еще больше масштабировались и работали над ImageNet, и тогда результаты стали действительно многообещающими.
Не могли бы вы рассказать нам о причастности Джеффа Дина (Jeff Dean)?
Ну, он меня очень поддержал. На самом деле я хочу отдать должное Джеффу Дину за его помощь в создании этой идеи.
Я обедал с Джеффом в 2014 году, и он поделился очень похожей интуицией. Он предположил, что если вы внимательно посмотрите на то, что исследователи делали в глубоком обучении в то время, они тратили много времени на настройку архитектуры гиперпараметров и так далее. Мы думали, что должен быть способ автоматизировать этот процесс. Джефф любит масштабировать и автоматизировать сложные вещи, которые большинство технических специалистов не любят делать. Джефф поддержал меня, и я, наконец, решил это сделать.

Насколько поиск нейронной архитектуры отличается от ваших предыдущих исследований?
Это отличается от того, что я делал раньше в компьютерном зрении. Это путешествие возникло из одной мысли и со временем росло. У меня тоже были кое-какие неправильные идеи. Например, я хотел автоматизировать и перестроить свертку, но это была неправильная интуиция. Может быть, мне следовало принять свертку, а затем использовать ее для построения чего-то другого? Это был процесс обучения для меня, но он был не так уж плох.
Технология
Какие компоненты нужны исследователю или инженеру для построения нейросетевой модели?
Он действительно немного отличается среди приложений, поэтому давайте сначала сузим его до компьютерного зрения — и даже в компьютерном зрении происходит много вещей. Как правило, в сверточной сети у вас есть вход, который является изображением, а затем у вас есть сверточный слой, а затем объединяющий слой, а затем пакетная нормализация. А потом есть функция активации, и вы решаете сделать пропуск соединения с новым слоем и тому подобное.
Внутри сверточных блоков у вас есть много дополнительных решений. Например, в свертке вы должны решить размер фильтра: это 1×1? 3×3? 5×5? Вы также должны принять решение о объединении и пакетной норме. Что касается пропуска соединения, то вы можете выбрать между первым и десятым слоями или между первым и вторым слоями. Таким образом, есть много решений, которые нужно принять, и большое количество общих возможных архитектур. Там может быть триллион возможностей, но люди сейчас смотрят только на крошечную часть того, что возможно.
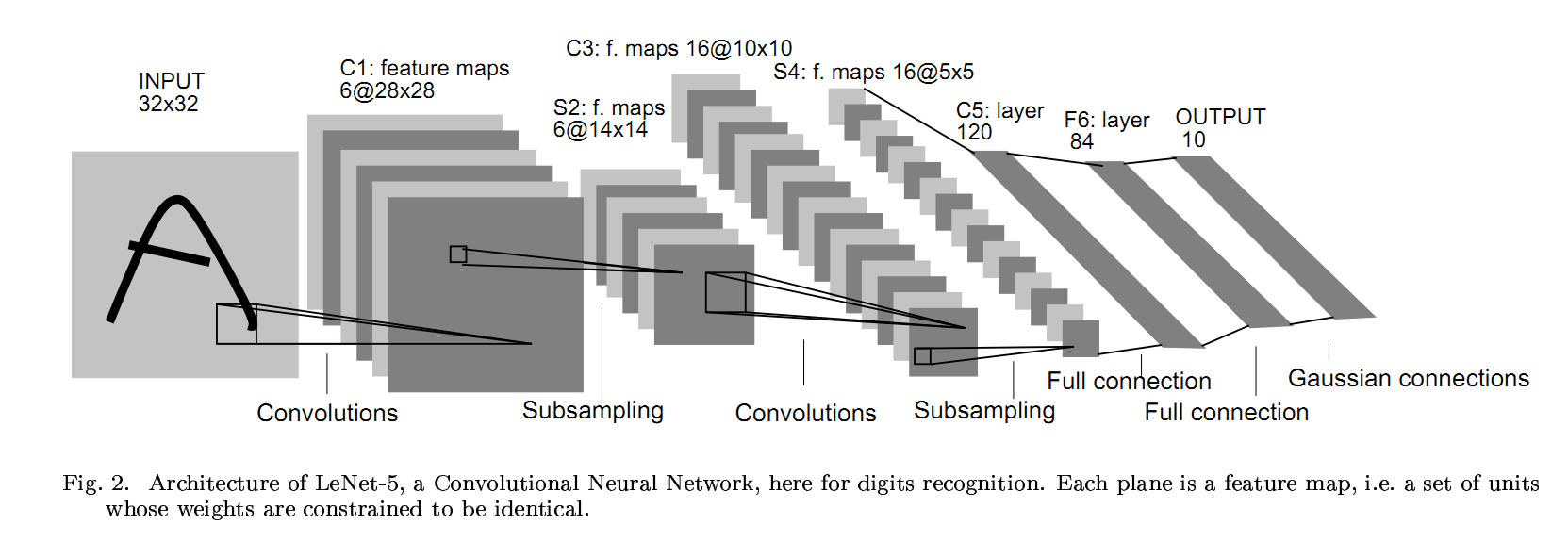
Свой первый документ о AutoML был нейронную архитектуру поиска (NAS) с подкреплением, опубликованные в 2016 году. С тех пор ваша команда приняла эволюционные алгоритмы и начала использовать прогрессивную нейронную архитектуру поиска. Не могли бы вы подробнее остановиться на этих улучшениях?
В оригинальной статье мы начали с обучения с подкреплением, потому что у нас была интуиция, что это по-человечески, вы можете использовать метод проб и ошибок. Но мне любопытно, поэтому я сказал " Хорошо, как насчет того, чтобы попробовать эволюцию?” Мы провели много экспериментов и добились некоторого успеха, и поняли, что процесс может быть выполнен с помощью эволюции, поэтому мы изменили основной алгоритм.
Одним из самых больших изменений стало использование ENAS (Efficient Neural Architecture Search). При создании большого количества архитектур каждая из них обучается и оценивается независимо по сравнению с предыдущим поколением. Таким образом, вы обычно не делитесь никакими предварительными знаниями или информацией. Но предположим, что вы действительно разрабатываете механизм совместного использования и что вы можете унаследовать некоторые веса от ранее обученной сети, тогда вы должны тренироваться быстрее. Так что мы сделали это.
В основном идея заключается в том, что вы создаете гигантскую сеть, которая имеет все возможности в ней, а затем ищете путь внутри сети (чтобы максимизировать ожидаемое вознаграждение за набор проверки), который является архитектурой, которую вы ищете. Некоторые веса будут использованы повторно для следующего эксперимента. Таким образом, происходит много обмена весом. Из-за этого мы действительно ускоряемся на много порядков. Оригинальный алгоритм NAS гораздо более гибок, но он слишком дорог. Это в основном новый и более быстрый алгоритм, но он также немного более ограничен.
Оригинальный алгоритм NAS мог бы генерировать лучшие архитектуры, а также лучшие гиперпараметры, лучшие стратегии увеличения данных, лучшую функцию активации, лучшую инициализацию и все остальное. До сих пор нам удавалось использовать новый алгоритм ENAS только для архитектур, а не для увеличения объема данных и не в качестве оптимизатора.
Вы имеете в виду, что другие компоненты генерируются людьми?
Мы определили архитектуру и расширение данных как две ключевые области, которые очень сложно спроектировать человеческим специалистам. Значит, ты получаешь много выгоды, как только ты исправляешь эти две вещи. Большую часть времени вы просто используете общую оптимизацию и стандартные практики. Мы просто концентрируемся на автоматизации компонентов, которые обеспечивают наибольшие преимущества.
ENAS до сих пор является новейшей разработкой. По-прежнему много экспериментов с черным ящиком, и исследования идут быстрыми темпами.
Я слышал, что один стартап сейчас использует технику, которая называется генеративный синтез. А может, и GAN? Какие плюсы и минусы различных алгоритмов поиска?
Я не слишком уверен насчет того, кто на самом деле использует GAN для создания архитектуры. Я думаю, что это возможно, хотя мне это менее знакомо.
Эволюция и подкрепляющее обучение также являются общими, но опять же, если вы не делаете никаких предположений, они могут быть довольно медленными. Таким образом, люди разработали идею прогрессивного поиска нейронной архитектуры, где они начинают искать небольшой компонент, а затем продолжают добавлять. Это одна из идей, которую я считаю очень хорошей.
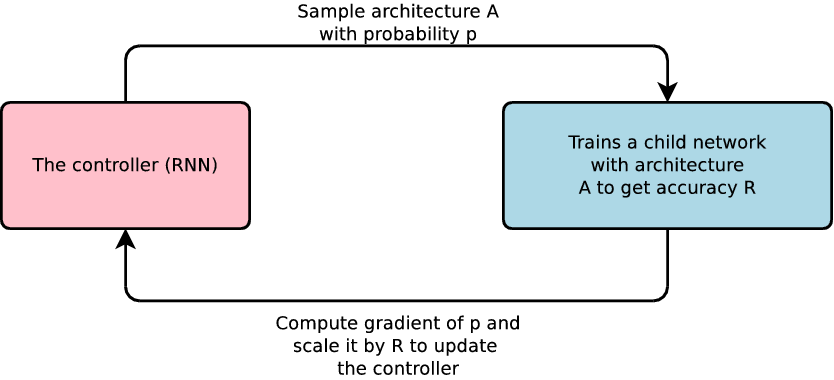
Говоря о ENAS, в основном основная идея заключается в разделении веса. Вы разрабатываете большую архитектуру, а затем один путь к ней. ENAS основана на ряде других идей, таких как поиск архитектуры с одним выстрелом, а именно: вы строите модели, а затем находите способ разделить вес между ними. Я думаю, что плюсы RL и эволюция в том, что они очень гибкие. Они могут быть использованы для автоматизации любого компонента в конвейере машинного обучения. Но они еще и очень дорогие. Большинство специфических алгоритмов, таких как ENAS и progressive architecture search, делают некоторые предположения, поэтому они менее универсальны и гибки, но обычно быстрее. Не знаю, как насчет Гана. Я думаю, что люди используют GAN для создания лучших изображений, но я не думаю, что они используют GAN для создания лучших архитектур.
Какую роль играет трансфертное обучение в технологии AutoML?
Существует два типа трансфертного обучения. Первый - это обучение передаче архитектуры, и под этим я подразумеваю, что вы находите хорошую архитектуру в наборе данных распознавания образов и переносите ее, например, на обнаружение объектов. Другой тип обучения переносу-это обучение переносу веса: у вас есть сеть, а затем вы предварительно тренируетесь на своем собственном наборе данных, а затем применяете его к своему небольшому набору данных.
Давайте создадим следующий сценарий: обнаружение цветов - это то, что мы хотим сделать. Ну, ImageNet имеет около миллиона изображений, а набор данных flower-это примерно 1k изображений или что-то в этом роде. Вы можете найти лучшую архитектуру из ImageNet, а затем повторно использовать веса; или вы можете просто взять современную модель, такую как Inception V3, и тренироваться на ImageNet, а затем передавать обучение на цветы, а затем повторно использовать веса. Распространенный метод-это просто перенос весов, потому что большинство людей не занимаются генерацией архитектуры. Вы должны взять свой Inception V3 или ResNet и тренироваться на ImageNet. После того, как вы закончили обучение, вы делаете тонкую настройку.
Я пытаюсь доказать, что на самом деле вам нужно как обучение переносу архитектуры, так и обучение переносу веса, которое можно объединить следующим образом:
- Комбинация первая: сначала вы изучаете архитектуру переноса, а затем учитесь переносу веса.
- Комбинация два: архитектурный поиск непосредственно в вашем наборе данных и обучение переносу веса в ImageNet.
- Комбинация три: в основном вы используете ResNet и обучение переносу веса. Это самое современное состояние.
- Комбинация ноль: просто поиск архитектуры без какого-либо обучения передаче в вашем целевом наборе данных.
Каждая из комбинаций варьируется между наборами данных, потому что иногда набор данных больше, а иногда меньше. Различные комбинации работают по-разному на разных сторонах набора данных.
Я предсказываю, что в ближайшие несколько лет комбинация Zero, чисто архитектурный поиск, будет производить сети лучшего качества. Мы провели много исследований в этой области и знаем, что на самом деле это лучше.

В исследовательской работе MIT и SJTU была предложена сеть уровня пути к сетевой трансформации.
Это хорошая идея. Когда я решил работать над поиском архитектуры, я хотел попробовать эту идею: вы начинаете с хорошей начальной архитектуры, а затем меняетесь и меняетесь, и стараетесь все время становиться лучше и лучше. Но я думал, что это было немного недвусмысленно, и я хотел что-то более амбициозное!
Самое приятное в написании статей то, что, когда мы публикуемся, у многих людей есть та же философия. И они вносят изменения в алгоритмы, а затем мы действительно учимся на этих исследовательских идеях и улучшаем наши исследования.
Какие части AutoML все еще требуют вмешательства человека?
Нам нужно немного поработать над проектированием пространства поиска. В архитектуре поиска у вас есть метод поиска, который является эволюцией, усилением обучения или эффективным алгоритмом. Но мы также должны определить пространство, где есть строительные блоки для сверточных сетей или полностью связанных сетей. Есть некоторые решения, которые необходимо принять, потому что прямо сейчас AutoML имеет ограниченные вычислительные возможности. Мы не можем просто искать все, потому что пространство слишком велико для нас. По этой причине мы должны спроектировать меньшее пространство поиска со всеми возможностями.
Глубокое обучение остается технологией черного ящика. Может ли AutoML помочь пользователям лучше понять модели?
Мы можем развить некоторые идеи. Например, процесс поиска будет генерировать множество архитектур, которые выглядят довольно похожими. Вы можете посмотреть на эти архитектуры и затем определить определенные шаблоны. Или вы можете развить интуицию относительно того, какая архитектура лучше всего подходит для вашего набора данных. Например, в ImageNet типичный слой в сети, найденный AutoML, имеет несколько ветвей (в отличие от более традиционных сетей, где каждый слой имеет одну ветвь или меньше ветвей). На уровне ветвей трудно объяснить, что происходит.
В возможность интеграции, размеров объектов и изображений различаются. Иногда у вас есть очень большой объект в центре изображения, а иногда у вас есть очень маленький объект, как маленькая часть изображения. Таким образом, у вас есть фильтры разного размера. Комбинируя различные ветви, вы получаете лучшие результаты. Мы будем продолжать заниматься этим вопросом.
Проблемы и будущее AutoML
В чем вы видите сегодня самую большую проблему в исследованиях AutoML?
В ближайшие пару лет, я думаю, самой большой проблемой будет то, как сделать поиск более эффективным, потому что не многие люди хотят использовать сотню графических процессоров для решения проблем на небольшом наборе данных. Поэтому выяснить, как сделать его еще менее дорогим, но без какого-либо компромисса с точки зрения качества, может быть очень большим вопросом.
Вторая большая проблема будет заключаться в том, как сделать пространство поиска немного менее ручным. Потому что пространство поиска прямо сейчас имеет некоторые предварительные знания. Таким образом, хотя мы и утверждаем, что делаем все AutoML, некоторые элементы предварительного знания попадают в пространство поиска. Я думаю, что это далеко не идеально, и я хочу работать над этим.
Но я могу сказать вам, что качество бета-версии AutoML было отличным, и облачные люди очень довольны. Я не могу вдаваться в детали продукта, но я думаю, что качество было отличным. И прием был также фантастическим.

Видите ли вы возможности для повышения надежности AutoML?
Обычно, когда мы выполняем AutoML, у нас есть отдельный набор данных проверки. Таким образом, мы можем продолжать проверять этот набор данных для оценки качества. Надежность на самом деле уже является частью целевой функции AutoML. Теперь с точки зрения дополнительных ограничений, таких как попытка сделать модели более устойчивыми к помехам от конкурентов, или если у вас есть другие ограничения, которые вы хотите свернуть в AutoML, оказывается, что AutoML имеет силу сделать это. Это особенно большая сила, потому что во многих случаях, когда у вас есть новое ограничение, очень трудно найти, как вставить его в модели. Оказывается, вы можете создать функцию вознаграждения, которая может быть компромиссом между точностью и надежностью. Затем он, наконец, будет развиваться, и вы найдете модель, которая имеет хороший компромисс между точностью и надежностью.
Позвольте мне привести вам пример. У нас был исследователь, который изучал, как разработать лучшие сети, чтобы предотвратить примеры состязательности. Мы сделали небольшой масштабный эксперимент на CIFAR10. Он смог найти сеть, которая очень устойчива к атакам противника, лучше, чем современное состояние. Результат был хорошим, и причина, по которой это сработало, заключается в том, что человеку очень трудно интуитивно придумать способ защиты от нападений. Но AutoML это не волнует, он просто пробует кучу сетей, а затем одна сеть каким-то образом внутренне имеет механизм предотвращения атак.
Можно ли эффективно сравнить различные решения AutoML, представленные в настоящее время на рынке?
Вы можете это сделать. Всякий раз, когда у вас есть задача, вы должны создать отдельный набор данных. Вы отправляете его в AutoML, и он может вернуться с некоторыми моделями прогнозирования, а затем вы получаете свои модели прогнозирования для оценки на вашем тестовом наборе, который будет считаться вашим золотым набором. Точность на этом золотом наборе-хороший способ измерить производительность. Я не могу очень много комментировать то, как мы выступаем против других игроков на рынке, но я думаю, что это доступно для людей, чтобы посмотреть и сравнить.
Как вы думаете, AutoML может создать следующую революционную сетевую архитектуру, такую как Inception или ResNet?
Я думаю, что это уже произошло. Недавно мы использовали архитектурный поиск, чтобы найти лучшие сети для мобильных телефонов. Это сложная и трудная область, и многие люди работают над ней. Трудно превзойти MobileNet v2, который сейчас является отраслевым стандартом. Мы создали сеть, которая значительно лучше, на два процента лучше с той же скоростью на мобильных телефонах.
И это только начало. Я думаю, что так оно и будет продолжаться. Я предсказываю, что через пару лет лучшие сети, по крайней мере в области компьютерного зрения, будут создаваться, а не создаваться вручную.
Как вы относитесь к шумихе вокруг AutoML?
Мне трудно комментировать шумиху вокруг AutoML, но когда я смотрю на количество людей, которые хотят использовать машинное обучение, я вижу, что есть много возможностей оказать влияние, сделав машинное обучение более доступным. Некоторые методы могут быть более раскрученными, чем другие, но со временем, я думаю, есть очень большая область, где мы можем оказать влияние.
Очень немногие исследователи неоднократно совершали прорывы в области машинного обучения. Как вы поддерживаете свой творческий потенциал?
Во-первых, есть много удивительных исследователей, которые чрезвычайно креативны и делают отличную работу, так что я бы не сказал, что я что-то особенное делал. Что касается меня, то у меня есть ряд проблем, которые мне всегда интересно решать, и я действительно люблю их решать. Это сочетание любопытства и настойчивости. Я просто хочу следовать своему любопытству и оказывать оложительное влияние на мир. Я также играю в футбол по выходным и люблю садоводство — я не знаю, помогает ли это моим исследованиям, но это действительно помогает мне немного расслабиться!
Я должен спросить: как вы справляетесь с неудачей?
Если вы любите что-то, тогда вы просто продолжите идти, верно? Так что я действительно люблю машинное обучение. Учить машины, как учиться-это новый способ делать компьютерное программирование: вместо того, чтобы писать программу, вы учите машину делать это. Мне нравится эта концепция на фундаментальном уровне. Так что даже когда есть неудача, я все равно получаю удовольствие!
Журналист: Тони Пэн / Редактор: Майкл Саразен
Источник: medium.com
#Google #ИИ #эксперт #Куок Ле #Quoc Le #Google AutoML #Google Brain
СТАТЬИ ПО ТЕМЕ
Хоанг Тхук Хао вошел в историю, став первым вьетнамским победителем Глобальной премии в области устойчивой архитектуры за новаторские проекты, ориентированные на человека и устойчивое развитие.
Основатель и председатель Vingroup Фам Нхат Выонг стал первым вьетнамцем, имеющим состояние в 9 миллиардов долларов, согласно обновлению Forbes в четверг, 8 мая.
1 месяц назад
Как и планировалось в 20:30 14 апреля 2025г., космическая туристическая компания американского миллиардера Джеффа Безоса Blue Origin провела свой 11-й пилотируемый полет на космическом корабле New Shepard, что станет первой полностью женской пилотируемой миссией с 1963 года.
2 месяца назад
Во Вьетнаме сейчас всего четыре миллиардера, что на одного меньше, чем в начале этой недели, после того, как фондовый рынок упал на историческую величину, поскольку инвесторы отреагировали на последние импортные тарифы Дональда Трампа.
2 месяца назад
Вьетнам теперь имеет пять миллиардеров в глобальном списке богачей Forbes после того, как Чан Ба Зыонг, председатель совета директоров автопроизводителя Thaco, выбыл из него в результате обновления 11 марта.
3 месяца назад
Согласно недавнему исследованию, во Вьетнаме в прошлом году насчитывалось 5 459 человек с состоянием в 10 миллионов долларов и выше, что является самым низким показателем в Юго-Восточной Азии.
3 месяца назад
Нгуен Данг Куанг, председатель совета директоров вьетнамского конгломерата Masan Group, вернулся в список американских компаний. долларовых миллиардеров, согласно последним данным Forbes.
4 месяца назад
Во Вьетнаме сейчас пять миллиардеров с общим состоянием в 12,4 миллиарда долларов после того, как один из них выбыл в этом месяце.
4 месяца назад
Вьетнамский профессор вошел в историю как первый вьетнамский главный редактор престижного научного журнала при Институте инженеров по электротехнике и электронике (IEEE).
5 месяцев назад
Согласно последнему обновлению Forbes, совокупные активы шести богатейших людей Вьетнама оценивались в общей сложности в 12,6 миллиарда долларов США на конец 2023 года, что на 5 миллиардов долларов меньше, чем в предыдущем году.
1 год назад